19 Cost-Effectiveness and Incremental Cost Analysis (CEICA) with ecorest
This module will teach you how to use the ecorest package in R to efficiently and reproducibly carry out Cost Effectivness and Incremental Cost Analysis (CEICA) and generate useful output like this in just a few lines of code:
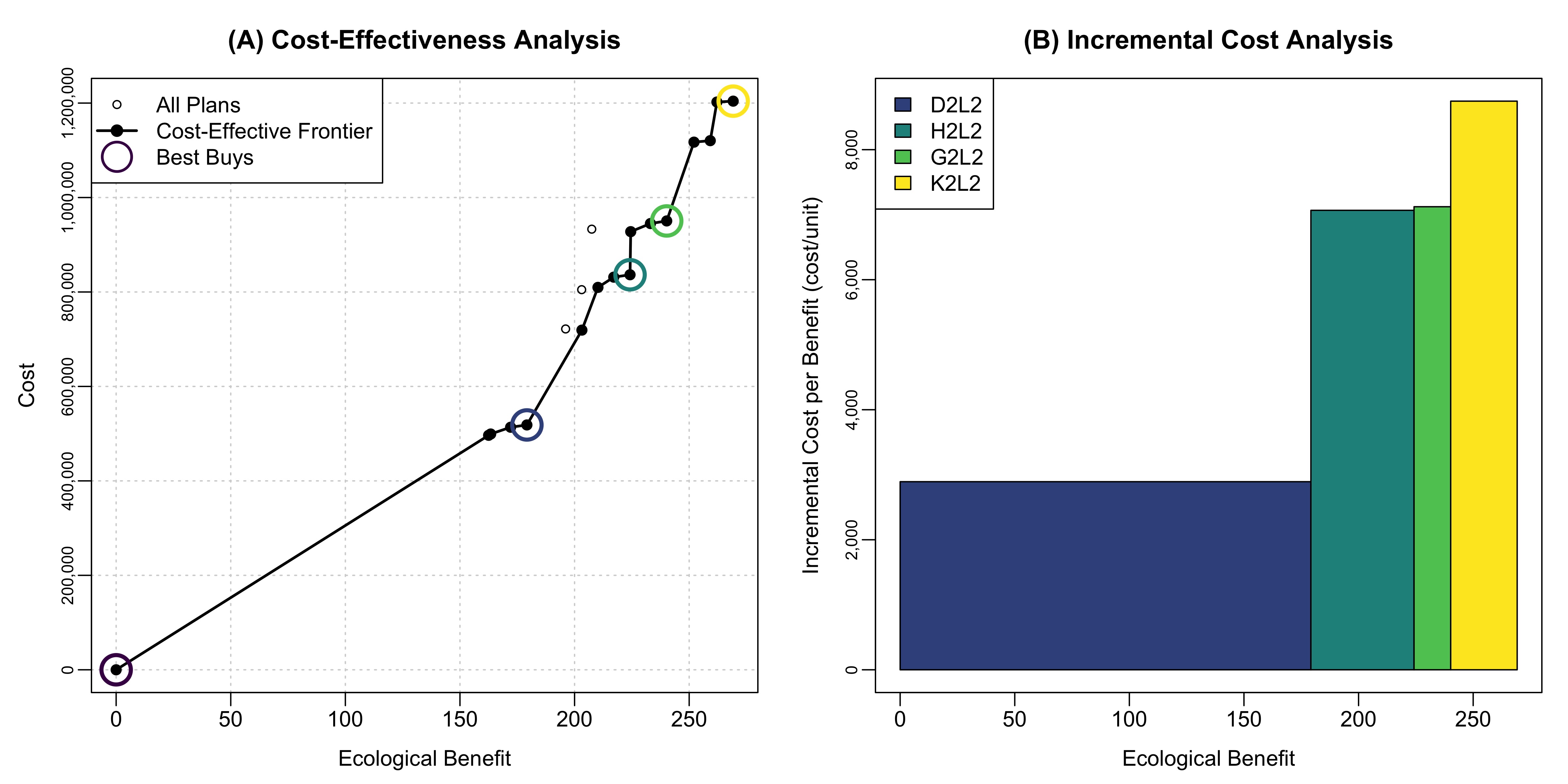
Authors: Ed Stowe (Writing, code), Darixa Hernandez-Abrams (writing, code), Kyle McKay (writing, code). CEICA background information was adapted from a draft tech report on the ecorest R package, authored by Kyle McKay, Darixa Hernández-Abrams, Rachel Nifong, and Todd Swannack
Last update: 2025-10-30
Acknowledgements:
19.1 Learning objectives
- Understand the purpose of Cost Effectiveness and Incremental Cost Analysis
- Understand what cost effective and best buy alternatives represent
- Learn how to use the
ecorestpackage to determine cost effective and best buy options
19.2 Background on Cost Effectivness and Incremental Cost Analysis
Cost-effectiveness and incremental cost analyses (CEICA) are analytical tools for assessing the relative benefits and costs of ecosystem restoration actions and informing decisions. Benefits and costs are assessed prior to these analyses using ecological models and cost engineering methods, respectively. CEICA may then be conducted at the site scale to compare alternatives at a single location (e.g., no action vs. dam removal vs. fish ladder) or at the system scale to compare relative merits of multiple sites (e.g., no sites vs. Site-A only vs. Site-B only vs. Site-A and Site-B).
Cost-effectiveness analysis provides a mechanism for examining the efficiency of alternative actions. For any given level of investment (i.e., cost), the agency wants to identify the plan with the most return-on-investment (i.e., the most environmental benefits), and for any given level of environmental benefits, the agency wants a plan with the least cost. An “efficiency frontier” identifies all plans that efficiently provide benefits on a per cost basis (i.e., cost-effective plans).
Incremental cost analysis is conducted on the set of cost-effective plans. This technique sequentially compares each plan to all higher cost plans to reveal changes in unit cost as output levels increase and eliminates plans that do not efficiently provide benefits on a per unit cost basis. Specifically, this analysis examines the slope of the cost-effectiveness frontier to isolate how the incremental unit cost ($/unit) increases as the magnitude of environmental benefit increases. Incremental cost analysis is ultimately intended to inform decision-makers about the consequences of increasing unit cost when increasing benefits (i.e., each unit becomes more expensive). Plans emerging from incremental cost analysis efficiently accomplish the objective relative to unit costs and are typically referred to as “best buys”. Importantly, all “best buys” are cost-effective, but all cost-effective plans are not best buys.
19.3 CEICA with ecorest in 4 easy steps!
Within the USACE, the Institute of Water Resources has provided a toolkit for conducting CEICA, the IWR Planning Suite (http://www.iwr.usace.army.mil/Missions/Economics/IWR-Planning-Suite/). However, CEICA can also be accomplished swiftly and easily using the ecorest package in R, with all the associated benefits that occur when conducting analyses programmatically in R (e.g., reproduciblilty, re-usable scripts, etc.).
Section 19.4 below walks through how CEICA works step-by-step so users can develop a deeper understanding of how CEICA works. But first in this section, we will demonstrate how easy the process is using functions from the ecorest package. The following code does everything one needs to determine which alternatives are cost effective and which are ‘best buys’, and to plot the results. For this demonstration, we will use data from the Beaver Island Habitat Rehabilitation and Enhancement Project, part of the Upper Mississippi River Restoration program.
First, we load the required packages and the Beaver Island cost-benefit data.
library(tidyverse)
library(ecorest)
library(knitr) # Needed to created quality tables
library(scales) # Needed to convert costs to dollars for table generation
# Most basic with Beaver Island
bi_cost_bens <- read_csv("data/beaver_island_cost_ben.csv") Let’s check out the cost-benefit data. To do this, we’ll first create a new dataframe that’s more suitable for an output table: we can classify the cost figures as being in dollars (using the scales package), and rename some of the columns so that they’re easier to interpret. Then we’ll use the kable function from the knitr package to view the table.
first_table <- bi_cost_bens %>%
mutate(AnnCost = dollar(AnnCost), # Format as dollars with scales package
AvgCost = dollar(AvgCost)) %>% # Format as dollars
rename("Alt. ID" = AltID,
"Description" = AltName,
"Rest. Benefit" = RestBen,
"Ann. Cost" = AnnCost,
"Avg. Cost" = AvgCost)
kable(first_table, padding = 2, align = "clccc")| Alt. ID | Description | Ann. Cost | Rest. Benefit | Avg. Cost |
|---|---|---|---|---|
| 0 | No Action Plan | $0 | 0.0 | $0 |
| D2L3 | Lower Cut, Stewart, Small, Riprap, Closure | $496,526 | 162.5 | $3,056 |
| D2L4 | Lower Cut, Stewart, Small, Riprap w/substrate, Closure | $499,260 | 163.4 | $3,055 |
| D2L1 | Lower Cut, Stewart, Small, Chevron, Closure | $513,615 | 172.1 | $2,984 |
| D2L2 | Lower Cut, Stewart, Small, Chevron w/substrate, Closure | $518,462 | 179.2 | $2,893 |
| E2L1 | Lower Cut, Blue Bell, Sand Burr, Chevron, Closure | $721,698 | 196.1 | $3,680 |
| F2L1 | Lower Cut, Stewart, Blue Bell, Sand Burr, Closure, Chevron | $804,896 | 203.1 | $3,963 |
| E2L2 | Lower Cut, Blue Bell, Sand Burr, Chevron w/substrate, Closure | $719,258 | 203.2 | $3,540 |
| F2L2 | Lower Cut, Stewart, Blue Bell, Sand Burr, Closure, Chevron w/substrate | $809,741 | 210.2 | $3,852 |
| H2L1 | Lower Cut, Blue Bell, Sand Burr, Lower Lake, Closure, Chevron | $831,390 | 217.1 | $3,830 |
| H2L2 | Lower Cut, Blue Bell, Sand Burr, Lower Lake, Closure, Chevron w/substrate | $836,488 | 224.2 | $3,731 |
| I2L3 | Lower Cut, Stewart, Blue Bell, Sand Burr, Lower Lake, Closure, Riprap | $927,732 | 224.5 | $4,132 |
| H2L3 | Lower Cut, Stewart, Blue Bell, Sand Burr, Lower Lake, Closure, Riprap w/substrate | $933,020 | 207.5 | $4,496 |
| G2L1 | Lower Cut, Stewart, Blue Bell, Sand Burr, Lower Lake, Closure, Chevron | $944,914 | 233.1 | $4,054 |
| G2L2 | Lower Cut, Stewart, Blue Bell, Sand Burr, Lower Lake, Closure, Chevron w/substrate | $950,447 | 240.2 | $3,957 |
| J2L1 | Lower Cut, Blue Bell, Sand Burr, Lower Lake, Upper Lake, Upper Cut, Closure, Chevron | $1,117,284 | 252.1 | $4,432 |
| J2L2 | Lower Cut, Blue Bell, Sand Burr, Lower Lake, Upper Lake, Upper Cut, Closure, Chevron w/substrate | $1,120,429 | 259.2 | $4,323 |
| K2L1 | Lower Cut, Stewart, Blue Bell, Sand Burr, Lower Lake, Upper Lake, Upper Cut, Closure, Chevron | $1,202,194 | 262.1 | $4,587 |
| K2L2 | Lower Cut, Stewart, Blue Bell, Sand Burr, Lower Lake, Upper Lake, Upper Cut, Closure, Chevron w/substrate | $1,204,094 | 269.2 | $4,473 |
To determine which project alternatives are cost effective, the ecorest package has a function called CEfinder. We can use the args() function to determine what inputs are needed for CEfinder and any other function.
args(CEfinder)## function (benefit, cost)
## NULLThe inputs consist of 2 vectors: 1) Project benefits; 2) Project annualized costs. We’ll make these vectors and then use these in the function.
benefits <- bi_cost_bens$RestBen
costs <- bi_cost_bens$AnnCost
restCE <- CEfinder(benefits, costs)
restCE## [1] 1 1 1 1 1 0 0 1 1 1 1 1 0 1 1 1 1 1 1We see that the restCE object is a vector of 1s and 0s, with 1s being cost effective options. This indicates that all but three of the options are cost-effective. But we still need to figure out which options are ‘best buys.’
To do this, we can use the BBfinder function. The inputs are again vectors of benefits and costs, as well as the vector of cost effectiveness scores that we’ve just created.
BB_list <- BBfinder(benefits, costs, restCE)
BB_list## [[1]]
## benefit cost CE BB
## [1,] 0.0 0 1 1
## [2,] 162.5 496526 1 0
## [3,] 163.4 499260 1 0
## [4,] 172.1 513615 1 0
## [5,] 179.2 518462 1 1
## [6,] 196.1 721698 0 0
## [7,] 203.1 804896 0 0
## [8,] 203.2 719258 1 0
## [9,] 210.2 809741 1 0
## [10,] 217.1 831390 1 0
## [11,] 224.2 836488 1 1
## [12,] 224.5 927732 1 0
## [13,] 207.5 933020 0 0
## [14,] 233.1 944914 1 0
## [15,] 240.2 950447 1 1
## [16,] 252.1 1117284 1 0
## [17,] 259.2 1120429 1 0
## [18,] 262.1 1202194 1 0
## [19,] 269.2 1204094 1 1
##
## [[2]]
## benefit cost inccost
## [1,] 0.0 0 0.000
## [2,] 179.2 518462 2893.203
## [3,] 224.2 836488 7067.244
## [4,] 240.2 950447 7122.438
## [5,] 269.2 1204094 8746.448The output of the BB_finder() function is a list comprised of two dataframes. The first data frame has columns for restoration benefits, costs, and whether alternatives are cost effective and best buys.
The second dataframe features the cost, benefit, and the incremental costs of each best buy compared to the previous best buy (i.e., the slope of the cost effectivness frontier). For example, the third best buy costs $318,026 more than the second best buy, and yields additional benefits of 45 habitat units. By dividing these incremental costs and benefits, we can see that the per-unit incremental cost of best buy three is $7,067.24. This is the cost for each additional unit of benefit beyond the second best buy.
Now that we’ve determined the cost effective and best buy options we can create a table of the output. Note: because the BB_list object is a list of two dataframes, we need to extract just the column of 1s and 0s indicating ‘best buy’ status. To do so, we use the code BB_list[[1]][,4], which pulls the first dataframe in the list (i.e., [[1]]), and then the fourth column of that dataframe (i.e., [,4]). See here for more information about subsetting with brackets.
We then create a new dataframe based on the earlier table that we created: we remove the ‘Description’ column to save space and add two new columns with the cost effectiveness and best buy information.
bb_vector <- BB_list[[1]][,4]
#Create a table of the results
ceica_table <- first_table %>%
dplyr::select(-Description) %>%
mutate(
"Cost Effectiveness" = restCE,
"Best Buy" = bb_vector)
kable(ceica_table, padding = 2, align = "lccccc")| Alt. ID | Ann. Cost | Rest. Benefit | Avg. Cost | Cost Effectiveness | Best Buy |
|---|---|---|---|---|---|
| 0 | $0 | 0.0 | $0 | 1 | 1 |
| D2L3 | $496,526 | 162.5 | $3,056 | 1 | 0 |
| D2L4 | $499,260 | 163.4 | $3,055 | 1 | 0 |
| D2L1 | $513,615 | 172.1 | $2,984 | 1 | 0 |
| D2L2 | $518,462 | 179.2 | $2,893 | 1 | 1 |
| E2L1 | $721,698 | 196.1 | $3,680 | 0 | 0 |
| F2L1 | $804,896 | 203.1 | $3,963 | 0 | 0 |
| E2L2 | $719,258 | 203.2 | $3,540 | 1 | 0 |
| F2L2 | $809,741 | 210.2 | $3,852 | 1 | 0 |
| H2L1 | $831,390 | 217.1 | $3,830 | 1 | 0 |
| H2L2 | $836,488 | 224.2 | $3,731 | 1 | 1 |
| I2L3 | $927,732 | 224.5 | $4,132 | 1 | 0 |
| H2L3 | $933,020 | 207.5 | $4,496 | 0 | 0 |
| G2L1 | $944,914 | 233.1 | $4,054 | 1 | 0 |
| G2L2 | $950,447 | 240.2 | $3,957 | 1 | 1 |
| J2L1 | $1,117,284 | 252.1 | $4,432 | 1 | 0 |
| J2L2 | $1,120,429 | 259.2 | $4,323 | 1 | 0 |
| K2L1 | $1,202,194 | 262.1 | $4,587 | 1 | 0 |
| K2L2 | $1,204,094 | 269.2 | $4,473 | 1 | 1 |
Finally, we can use the CEICAplotter function to create and save plots depicting the results of the cost effectiveness analysis, and the incremental cost analysis. The five required inputs for this function are the project alternative names (which we can pull from our original dataframe using bi_cost_bens$AltID), benefits, annualized costs, cost effectiveness scores, best buy scores, and a file name for the plot. The plot will be created in the user’s working directory with a filename of their choice.
# Create a plot of CEICA results
CEICAplotter(bi_cost_bens$AltID, benefits, costs, restCE, bb_vector, "images/CEICAexample1.jpeg")And that’s it! If a user has cost and benefit data, three functions are all it takes to find cost effective (CEfinder) and best buy options (BBfinder), and to create a plot of the overall CEICA results (CEICAplotter). And if the underlying cost or benefit data were to change, the R script can instantly update the output with the new data.
19.4 CEICA in depth
We’ve seen that CEICA can be accomplished very quickly with the above code. However, if a user wishes to understanding how projects are determined to be cost effective or best buys, we go into greater depth here.
19.4.1 Identifying cost effective alternatives
The first component of CEICA is the cost effectiveness analysis.
Here, for each alternative, we ask: are there any alternatives that produce higher ecological outcomes for equal or lower costs? If the answer is yes, that alternative is considered non-cost effective.
Non-cost effectiveness can be though of in two ways:
* Inefficient in Production: any alternative where the same output level can be generated at a lesser cost by another alternative.
* Ineffective in Production: any alternative where a greater output level can be generated at a lesser or equal cost by another alternative.
Let’s look more closely at the cost/benefit data above:
| AltID | AnnCost | RestBen |
|---|---|---|
| 0 | 0 | 0.0 |
| D2L3 | 496526 | 162.5 |
| D2L4 | 499260 | 163.4 |
| D2L1 | 513615 | 172.1 |
| D2L2 | 518462 | 179.2 |
| E2L1 | 721698 | 196.1 |
| F2L1 | 804896 | 203.1 |
| E2L2 | 719258 | 203.2 |
| F2L2 | 809741 | 210.2 |
| H2L1 | 831390 | 217.1 |
| H2L2 | 836488 | 224.2 |
| I2L3 | 927732 | 224.5 |
| H2L3 | 933020 | 207.5 |
| G2L1 | 944914 | 233.1 |
| G2L2 | 950447 | 240.2 |
| J2L1 | 1117284 | 252.1 |
| J2L2 | 1120429 | 259.2 |
| K2L1 | 1202194 | 262.1 |
| K2L2 | 1204094 | 269.2 |
The first alternative, with a cost of $0, will be considered cost effective, because there are no projects of lesser or equal cost. So let’s look at the second option to see if it’s cost effective. To do so, we will first see which alternatives have greater benefits, because if any alternatives have greater benefits at the same or lower cost, then option 2 is not cost effective.
# Vectors defined to make calculations easier
benefits <- bi_cost_bens$RestBen
costs <- bi_cost_bens$AnnCost
# Which projects have greater than or equal benefits than the second project's benefits
greater_bens <- which(benefits >= benefits[2])
greater_bens## [1] 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19The which function is used to return all the positions (e.g., the first number, the second, and so on) within the benefit vector in which the benefits are greater than or equal to the benefits of the second option in the vector (i.e., benefit[2]).
Looking at the output, we see that all other projects have greater than or equal benefits than alternative #2.
Now, we’re looking to see if there are any projects with equal or greater benefits but for lower costs.
which(costs[greater_bens] <= costs[2])## [1] 1A value of 1 indicates that only the cost in the first position (i.e., alternative #2’s own cost) is less than or equal. In other words, no alternatives with greater or equal benefits cost less or the same, meaning that this is a cost effective option. We stoll don’t know though if it is a best buy.
Let’s look at a different alternative using the same code: Alternative E2L1, which is the sixth alternative:
## [1] 1 3This suggests that another alternative with a greater or equal level of benefits costs less than or the same as E2L1. The index value of 3 (compared to the index value of 1 for E2L1), suggests that it’s two projects after E2L1 in the project list: E2L2, which has a lower cost but higher benefit. Therefore, E2L1 will not be considered cost effective.
We could do what we’ve just done for each project, but that would take time and be tedious. Instead, we can iterate through all the projects by using a ‘for-loop’, as the following code indicates:
# Set up empty vector to store whether each alternative is cost effective
CE <- c()
# Iterate through each project to see if another project renders that one cost ineffective
# An ifelse statement assigns a value of 1 to projects that are cost effective, and 0 to ones that are not
for (i in 1:length(benefits)) {
bigben <- which(benefits >= benefits[i])
CE[i] <- ifelse(length(which(costs[bigben] <= costs[i])) ==
1, 1, 0)
}
cbind(bi_cost_bens$AltID, CE)## CE
## [1,] "0" "1"
## [2,] "D2L3" "1"
## [3,] "D2L4" "1"
## [4,] "D2L1" "1"
## [5,] "D2L2" "1"
## [6,] "E2L1" "0"
## [7,] "F2L1" "0"
## [8,] "E2L2" "1"
## [9,] "F2L2" "1"
## [10,] "H2L1" "1"
## [11,] "H2L2" "1"
## [12,] "I2L3" "1"
## [13,] "H2L3" "0"
## [14,] "G2L1" "1"
## [15,] "G2L2" "1"
## [16,] "J2L1" "1"
## [17,] "J2L2" "1"
## [18,] "K2L1" "1"
## [19,] "K2L2" "1"For each iteration of the for-loop (i.e., for all values of i from 1 to 19), we run essentially the same code as above. The if-else statement indicates that if the length of the second vector produced above is 1 (as it was with the first alternative above), the project is cost effective and we will assign a value of 1 to the CE vector. However, if the length of second vector is not 1 (as it was for alternative E2L1), the project is not cost-effective and we will assign it a 0.
Using the for-loop thus lets us quickly determine which alternatives are cost-effective and which are not.
19.4.2 Identifying ‘best buys’
Identifying best buys is a matter of finding which of the cost effective alternatives can increase environmental benefits at the lowest incremental cost (i.e., lowest cost per additional habitat unit).
The first best buy is always the one with the lowest average cost after 0.
To find all of the best buys, we can start again with our vectors of benefits and costs, but now we will subset these to include just the cost effective options, and then reorder the benefits and costs from lowest to greatest cost.
# Subset to cost effective options
ben.CE <- benefits[which(CE == 1)]
cost.CE <- costs[which(CE == 1)]
# Reorder benefits and costs from lowest to greatest cost
ben.CE2 <- ben.CE[order(cost.CE)]
cost.CE2 <- cost.CE[order(cost.CE)]All costs and benefits are greater than the first cost effective option (i.e., the $0 cost-0 benefit future without project or FWOP), so we now calculate the incremental costs: this is the difference in costs among subsequent alternatives, divided by the difference in benefits among subsequent alternatives. The cost.CE2[-1] and ben.CE2[-1] code are the costs and benefits except for the first item in the list, (i.e., costCE2[1]).
## [1] "$3,055.54" "$3,055.45" "$2,984.40" "$2,893.20" "$3,539.66" "$3,852.24" "$3,829.53" "$3,730.99"
## [9] "$4,132.44" "$4,053.69" "$3,956.90" "$4,431.91" "$4,322.64" "$4,586.78" "$4,472.86"We want to find the lowest incremental cost after the FWOP. Eyeballing the list, we can see it’s the fourth cost, but we can also do this using the code. To find the project this corresponds to, we need to add 1 to this value, because the incremental costs above do not include the first project, i.e., the FWOP.
## [1] 5This indicates that the fifth alternative is the second best-buy after the FWOP.
To look for the next best buy, we want to just look at projects after the fifth project. We first generate cost and benefit vectors for the projects after alternative five. And then we calculate incremental costs for projects above the fifth alternative. The values in the bracket [-1:-5] indicate to remove the first five values from these vectors.
ce.ben.temp <- ben.CE2[-1:-5] # Selects all the project benefits with greater benefits than the current best buy
ce.cost.temp <- cost.CE2[-1:-5] # All the project costs with greater costs than current best buy
inccost <- (ce.cost.temp - cost.CE2[5])/(ce.ben.temp - ben.CE2[5]) # calculate avg. costs from each costlier option compared to the current best buy
inccost %>% dollar()## [1] "$8,366.50" "$9,396.10" "$8,256.68" "$7,067.24" "$9,034.66" "$7,911.91" "$7,081.72" "$8,214.29"
## [9] "$7,524.59" "$8,247.67" "$7,618.13"This is our new vector of incremental costs for projects subsequent to the fifth alternative.
Again, we wish to find the lowest incremental cost after this alternative, so we use the same code as previously, except here, we need to add 5 (because we are considering only projects after the fifth alternative)
## [1] 9This indicates that the 9th option (among the cost effective alternatives) is the next one that is a best buy.
The user could iterate in this way through all the options. But as previously noted, when iterations are required, this is often a great time to use for-loops. The following code accomplishes this. Most of this code is nearly identical to what we’ve already run. The main difference is the use of the BB vector to store which alternatives are best buys and to be sure that for each iteration, the new set of alternatives to consider are exclusively the subsequent iterations. Note, at the end of the loop code, there is an if statement that ends (i.e., breaks) the for-loop if the BB vector length is equal or greater than the total number of cost effective options (nCE) (i.e., if you get to the end of the vector of projects).
BB <- c(1) # Create vector to store BB index positions; the lowest cost option (i.e., position 1 is always a best-buy)
nCE <- length(ben.CE)
for (i in 1:nCE) {
ce.bentemp <- ben.CE2[-1:-BB[i]] # Selects all the project benefits with greater benefits than the current best buy
ce.costtemp <- cost.CE2[-1:-BB[i]] # All the project costs with greater costs than current best buy
inccost <- (ce.costtemp - cost.CE2[BB[i]])/(ce.bentemp - ben.CE2[BB[i]]) # calculate incr. costs from each subsequent option compared to the current best buy
BB[i + 1] <- which(inccost == min(inccost)) + BB[i] # Of all the incremental costs above this best_buy, which has the lowest?
if (BB[i + 1] >= nCE) {
break
}
}
BB## [1] 1 5 9 12 16This indicates that the best buys are in positions 1, 5, 9, 12, and 16 of the cost effective projects, (not the total list of projects).
To see which projects those are out of our overall list we can run the following code. We start with our original cost-benefit dataframe bi_cost_bens, add the cost effectiveness vector CE and then filter to just the cost effective options and finally arrange by cost (since we previously sorted in this way when finding the best buys). Our best buys are now just the project alternatives in the rows identified by the BB vector (i.e., rows: 1, 5, 9, 12, 16), so we can use the dplyr::slice() function to filter to just those rows. Finally we use pull() to create a vector of just the alternative IDs that are the best buys.
BB_IDs <- bi_cost_bens %>% # Start with the original data frame
mutate(cost_eff = CE) %>% # Add a column of the cost effectiveness scores
filter(cost_eff == 1) %>% # Filter to just the cost effective options
arrange(AnnCost) %>% # Arrange by cost
slice(BB) %>% # Keep rows in the positions identified by BB
pull(AltID) # Pull the alternative names out
BB_IDs## [1] "0" "D2L2" "H2L2" "G2L2" "K2L2"If we want to view these results in tabular form as we did previously, we can again make a new dataframe with the alternative IDs, the costs and benefits, which options are cost-effective, and which are best buys; and print it using the kable() function. To create the best_buy column, we use an if-else function that scores the row a 1 if that row’s Alt ID is in the vector BB_IDs and otherwise codes the row as a 0.
first_table %>%
dplyr::select(-Description) %>%
mutate("Cost Effective" = CE,
"Best Buy" = ifelse(`Alt. ID` %in% BB_IDs, 1, 0)) %>%
knitr::kable(padding = 2, align = "c")| Alt. ID | Ann. Cost | Rest. Benefit | Avg. Cost | Cost Effective | Best Buy |
|---|---|---|---|---|---|
| 0 | $0 | 0.0 | $0 | 1 | 1 |
| D2L3 | $496,526 | 162.5 | $3,056 | 1 | 0 |
| D2L4 | $499,260 | 163.4 | $3,055 | 1 | 0 |
| D2L1 | $513,615 | 172.1 | $2,984 | 1 | 0 |
| D2L2 | $518,462 | 179.2 | $2,893 | 1 | 1 |
| E2L1 | $721,698 | 196.1 | $3,680 | 0 | 0 |
| F2L1 | $804,896 | 203.1 | $3,963 | 0 | 0 |
| E2L2 | $719,258 | 203.2 | $3,540 | 1 | 0 |
| F2L2 | $809,741 | 210.2 | $3,852 | 1 | 0 |
| H2L1 | $831,390 | 217.1 | $3,830 | 1 | 0 |
| H2L2 | $836,488 | 224.2 | $3,731 | 1 | 1 |
| I2L3 | $927,732 | 224.5 | $4,132 | 1 | 0 |
| H2L3 | $933,020 | 207.5 | $4,496 | 0 | 0 |
| G2L1 | $944,914 | 233.1 | $4,054 | 1 | 0 |
| G2L2 | $950,447 | 240.2 | $3,957 | 1 | 1 |
| J2L1 | $1,117,284 | 252.1 | $4,432 | 1 | 0 |
| J2L2 | $1,120,429 | 259.2 | $4,323 | 1 | 0 |
| K2L1 | $1,202,194 | 262.1 | $4,587 | 1 | 0 |
| K2L2 | $1,204,094 | 269.2 | $4,473 | 1 | 1 |
19.5 Summary
- Cost-effectiveness analysis provides a mechanism for examining the efficiency of alternatives.
- Alternatives are cost effective if there aren’t any alternatives that produce higher ecological outcomes for ≤ costs
- Not all cost effective options are best buys; these are only the options with the lowest incremental costs compared to the previous best buy
- The
ecorestpackage provides a simple and easy set of functions for determining which project alternatives are cost effective and which are best buys and for plotting these results